2010 was the year that collaborative manuscript transcription finally caught on.
Back when I started work on FromThePage in 2005, I got the same response from most people I told about the project: "Why don't you just use OCR software?" To say that the challenges of digitizing handwritten material were poorly understood might be inaccurate—after all the TEI standard included an entire
chapter on manuscripts—but there were no tools in use designed for the purpose. Five years later, half a dozen web-based transcription projects are in progress and new projects may choose from several existing tools to host their own. Crowdsourced transcription was even the
written up in the New York Times!
I'm going to review the field as I see it, then make some predictions for 2011.
Ongoing Structured Transcription Projects
By far the most successful transcription project is
FamilySearch Indexing. In 2010,
185,900,667 records were transcribed from manuscript census forms, parish registers, tithe lists, and
other sources world-wide. This brings the total up to 437,795,000 records double-keyed and reconciled by more than
four hundred thousand volunteers — itself an awe-inspiring number with an
equally impressive support structure.
October saw the launch of
OldWeather, a project in which
GalaxyZoo applied its crowdsourcing technology to transcription of Royal Navy ship's logs from WWI. As I write, volunteers have transcribed an astonishing
308169 pages of logs — many of which include multiple records. I hope to do a more detailed review of the software soon, but for now let me note how elegantly the software uses the data itself to engage volunteers, so that transcribers can see the motion of "their ship" on a map as they enter dates, latitudes and longitudes. This leverages the immersive nature of transcription as an incentive, projecting users deep within history.
The
North American Bird Phenology Program transcribed nearly 160,000 species sighting cards between December 2009 and 2010 and maintained their reputation as a model for crowdsourcing projects by publishing the
first user satisfaction survey for a transcription tool. Interestingly the program seems to have followed a growth pattern a bit similar to Wikipedia's, as the cards transcribed rose from
203,967 to 362,996 while the number of volunteers only increased from
1,666 to 2,204 (32% vs 78%) — indicating that a core of passionate volunteers remain the most active contributors.
I've only recently discovered
Demogen, a project operated by the
Belgium Rijksarchief to enlist the public to index handwritten death notices. Although most of the documentation is in Flemish, the
Windows-based transcription software will also operate in French. I've had trouble finding statistics on how many of the record sets have been completed (a set comprising a score of pages with half a dozen personal records per page). By my crude estimate, the 4000ish sets are approximately 63% indexed — say a total of 300,000 records to date. I'd like to write a more detailed review of Demogen/Visu and would welcome any pointers to project status and community support pages.
Ancestry.com's
World Archives Project has been operating since 2008, but I've been unable to find any statistics on the total number of records transcribed. The project allows volunteers to index personal information from a fairly
heterogeneous assortment of records scanned from microfilm. Each set of records has its own
project page with
help and statistics. The keying
software is a Windows-based application free for download by any Ancestry.com registered user, while support is provided through
discussion boards and a wiki.
Ongoing Free-form Transcription Projects
While
I've written about
Wikisource and its
ProofreadPage plug-in before, it remains worth very much following.
More than two hundred thousand scanned pages have been proofread, had problems reconciled, and been reviewed out of 1.3 million scanned pages. Only a tiny percent of those are handwritten, but that's still a few thousand pages, making it the most popular automated free-form transcription tool.
This blog was started to track my own work developing
FromThePage to transcribe
Julia Brumfield's diaries. As I type,
beta.fromthepage.com hosts 1503 transcribed pages—of which 988 are indexed and annotated—and volunteers are now waiting on me to prepare and upload more page images.
Major developments in 2010 included the
release of FromThePage on GitHub under a Free software license and installation of the software by the Balboa Park Online Collaborative for transcription projects by their member institutions.
Probably the biggest news this year was
TranscribeBentham, a project at
University College London to crowdsource the transcription of Jeremy Bentham's papers. This involved the development of
Transcription Desk, a MediaWiki-based tool which is slated to be released under an open-source license. The team of volunteers had transcribed 737 pages of very difficult handwriting when I last consulted the
Benthamometer. The Bentham team has done more than any other transcription tool to publicize the field -- explaining their work on their
blog, reaching out through the media (including articles in the
Chronicle of Higher Education and the New York Times), and even highlighting other transcription projects on
Melissa Terras's blog.
Halted Transcription Projects
The
Historic Journals project is a
fascinating tool for indexing—and optionally transcribing—privately-held diaries and journals. It's run by Doug Kennard at at Brigham Young University, and you can read about his vision in
this FHT09 paper. Technically, I found a couple of aspects of the project to be particularly innovative. First, the software integrates with ContentDM to display manuscript page images from that system within its own context. Second, the tool is tightly integrated with FamilySearch, the LDS Church's database of genealogical material. It uses the FamilySearch API to perform searches for personal or place names, and can then use the FamilySearch IDs to uniquely identify subjects mentioned within the texts. Unfortunately, because the
FamilySearch API is currently limited to LDS members, development on Historic Journals has been temporarily halted.
Begun as a desktop application in 1998, the
uScript Transcription Assistant is the longest-running program in the field. Recently ported over to modern web-based technologies, the system is similar to
Img2XML and T-PEN in that it links individual transcribed words to the corresponding images within the scanned page. Although the system is not in use and
the source-code is not accessible outside WPI, you can read papers describing it by WPI
students in 2003 or
in 2005 by Fabio Carrera (the faculty member leading the project). Unfortunately,
according to Carrera's blog work on the project has stopped for lack of funding.
According to the New York Times article, there was an attempt to crowdsource the
Papers of Abraham Lincoln. The article quotes project director Daniel Stowell explaining that nonacademic transcribers "produced so many errors and gaps in the papers that 'we were spending more time and money correcting them as creating them from scratch.'" The
prototype transcription tool (created by NCSA at UIUC) has been abandoned.
Upcoming Transcription ProjectsThe Center for History and New Media at George Mason University is developing a transcription tool called
Scripto based on MediaWiki and architected around integration with an external CMS for hosting page images. The initial transcription project will be their
Papers of the War Department site, but connector scripts for other content management systems are under development. Scripto is being developed in a particularly open manner, with the source code available for immediate inspection and download on
GitHub and a
project blog covering the tool's progress.
T-PEN is a tool under development by Saint Louis Univiersity to enable line-by-line transcription and paleographic annotation. It's focused on medieval manuscripts, and automatically identifies the lines of text within a scanned page — even if that page is divided into columns. The team integrated crowdsourcing into their development process by challenging the public to test and give feedback on their line identification algorithm, gathering perhaps a thousand ratings in a two week period. There's no word on whether T-PEN will be released under a free license. I should also mention that they've got the
best logo of any transcription tool.
I covered
Militieregisters.nl at length
below, but the most recent news is that a vendor
has been picked to develop the
VeleHanden transcription tool. I would not be at all surprised if 2011 saw the deployment of that system.
The
Balboa Park Online Collaborative is going into collaborative transcription in a big way with the
Field Notes of Laurence Klauber for the San Diego Natural History Museum. They've picked my own FromThePage to host their transcriptions, and have been driving a lot of the development on that system since October through their enthusiastic feature requests, bug reports, and funding. Future transcription projects are in the early planning stages, but we're trying to complete features suggested by the Klauber material first.
The
University of Iowa Libraries plan to crowdsource transcription of their
Historic Iowa Children's Diaries. There is no word on the technology they plan to use.
The
Getty Research Institute plans to crowdsource transcription of
J. Paul Getty's diaries. This project also appears to be in the very early stages of planning, with no technology chosen.
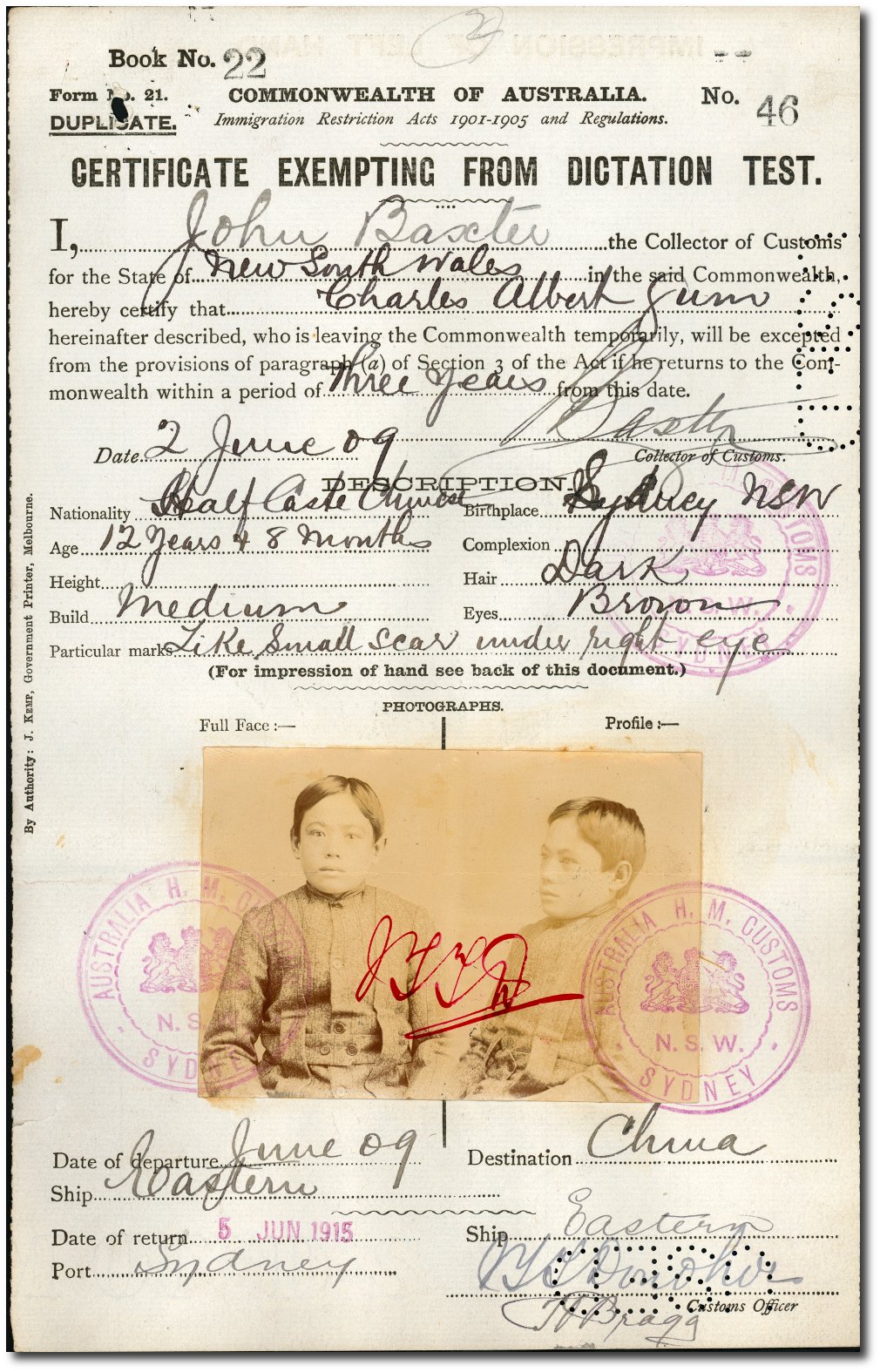
Invisible Australians is a digitization project by
Kate Bagnall and
Tim Sherratt to explore the lives of Australians subjected to the White Australia policy through their extensive records. While it's still in the planning stages (with only a
set of
project blogs and a
Zotero library publicly visible), the heterogeneity of the source material make it one of the most ambitious documentary transcription projects I've seen. Some of the data is traditionally structured (like
government forms), some free-form (like
letters), and there are photographs and even hand-prints to present alongside the transcription! Invisible Australians will be a fascinating project to follow in 2011.
Obscure Transcription Projects
Because the field is so fragmented, there are a number of projects I follow that are not entirely automated, not entirely public, not entirely collaborative, moribund or awaiting development. In fact, some projects have so little written about them online that they're almost mysterious.
- Commenters to a blog post at Rogue Classicism are discussing this APA job posting for a Classicist to help develop a new GalaxyZoo project transcribing the Oxyrhynchus Papyri.
- Some cryptic comments on blog posts covering TranscribeBentham point to FadedPage, which appears to be a tool similar to Project Gutenberg's Distributed Proofreaders. Further investigation has yielded no instances of it being used for handwritten material.
- A blog called On the Written, the Digital, and the Transcription tracks development of WrittenRummage, which was apparently a crowdsourced transcription tool that sought to leverage Amazon's Mechanical Turk.
- Van Papier Naar Digitaal is a project by Hans den Braber and Herman de Wit in which volunteers photograph or scan handwritten material then send the images to Hans. Hans reviews them and puts them on the website as a PDF, where Herman publicizes them to transcription volunteers. Those volunteers download the PDF and use Jacob Boerema's desktop-based Transcript software to transcribe the records, which are then linked from Digitale Bronbewerkinge Nederland en België. With my limited Dutch it is hard for me to evaluate how much has been completed, but in the years that the program has been running its results seem to have been pretty impressive.
- BYU's Immigrant Ancestors Project was begun in 1996 as a survey of German archival holdings, then was expanded into a crowdsourced indexing project. A 2009 article by Mark Witmer predicts the immanent roll-out of a new version of the indexing software, but the project website looks quite stale and says that it's no longer accepting volunteers.
- In November, a Google Groups post highlighted the use of Islandora for side-by-side presentation of a page image and a TEI editor for transcription. However I haven't found any examples of its use for manuscript material.
- Wiktenauer is a MediaWiki installation for fans of western martial arts. It hosts several projects transcribing and translating medieval manuals of fighting and swordsmanship, although I haven't yet figured out whether they're automating the transcription.
- Melissa Terras' manuscript transcription blog post mentioned a Drupal-based tool called OpenScribe, built by the New Zealand Electronic Text Centre. However, the Google Code site doesn't show any updates since mid-2009, so I'm not sure how active the project is. This project is particularly difficult to research because "OpenScribe" is also the name chosen for an audio transcription tool hosted on SourceForge as well as a commercial scanning station.
I welcome any corrections or updates on these projects.
Predictions for 2011
Emerging Community
Nearly all of the transcription projects I've discussed were begun in isolation, unaware of previous work towards transcription tools. While I expect this fragmented situation to continue--in fact I've seen isolated proposals as recently as
Shawn Moore's October 12 HASTAC post--it should lessen a bit as toolmakers and project managers enter into dialogue with each other on
comment threads,
conference panels or
GitHub. Tentative steps were made towards overcoming linguistic division in 2010, with Dutch archivists covering TranscribeBentham and a scattered bit of bloggy conversation between Dutch, German, English and American participants. The publicity given to projects like OldWeather, Scripto, and TranscribeBentham can only help this community form.
No Single Tool
We will not see the development of a single tool that supports transcription of both structured and free-form manuscripts, nor both paleographic and semantic annotation in 2011. The field is too young and fragmented -- most toolmakers have enough work providing the basic functionality required by their own manuscripts.
New Client-side Editors
Although I don't foresee convergence of server tools, there is already some exciting work being done towards Javascript-based editors for TEI, the mark-up language that informs most manuscript annotation.
TEILiteEditor is an open-source WYSIWYG for editing TEI, while
RaiseXML is an open-source editor for manipulating TEI tags directly. Both projects have seen a lot of activity over the past few weeks, and it's easy to imagine a future in which many different transcription tools support the same user-facing editor.
External Integration
2010 already saw strides being made towards integration with external CMSs, with BYU's Historic Journals serving page images from ContentDM and FromThePage serving page images from the Internet Archive. Scripto is apparently designed entirely around CMS integration, as it does not host images itself and is architected to support connectors for many different content management systems. I feel that this will be a big theme of transcription tool development in 2011, with new support for feeding transcriptions and text annotations back to external CMSs.
Outreach/Volunteer Motivation
We're learning that a key to success in crowdsourcing projects is recruiting volunteers. I think that 2011 will see a lot of attention paid to identifying and enlisting existing communities interested in the subject matter for a transcription project. In addition to finding volunteers, projects will better understand volunteer motivation and the trade-offs between game-like systems that encourage participation through score cards and points on the one hand, and immersive systems that enhance the volunteers' engagement with the text on the other.
Taxonomy
As number of transcription projects multiplies, I think that we will be able to start generalizing from the unique needs of each collection of manuscript material to form a sort of taxonomy of transcription projects. In the list above, I've separated the projects indexing structured data like militia rolls from those dealing with free-form text like diaries or letters. I think that in 2011 we'll be able to classify projects by their paleographic requirements, the kinds of analysis that will be performed on the transcribed texts, the quantity of non-textual images that must be incorporated into the transcription presentation, and other dimensions. It's possible that the existing tools will specialize in a few of these areas, providing support for needs similar to those of their original project so that a sort of decision tree could guide new projects toward the appropriate tool for their manuscript material.
2011 is going to be a great year!
{kind=link}
{kind=link}
{kind=link}