I've downloaded and played around with FamilySearch Indexer, and I must report that it's really impressive. Initially I was dismayed by the idea of collaborative transcription on a thick (desktop!) client, but my trial run showed me why it's necessary for their problem domain. Simply put, FSI is designed for forms, not freeform manuscripts like letters.
The problem transcribing forms is the structured nature of the handwritten data. An early 20th century letter written in a clear hand may be accurately represented by a smallish chunk of ASCII text. The only structures to encode are paragraph and page breaks. Printed census or military forms are different — you don't want to require your transcribes to type out "First Name" a thousand times, but how else can you represent the types of data recorded by the original writer?
FamilySearch Indexer turns this problem into an advantage. They've realized that scanned forms are a huge corpus of identically formatted data, so it pays off to come up with an identical structure for the transcription. For the 1900 Virginia census form I tested, someone's gone through the trouble to enter the metadata describing every single field for a fifty-line, twentyish-column page. The image appears in the top frame of the application and you enter the transcription in a spreadsheet-style app in the bottom-left frame. As you tab between fields, context-sensitive help information appears in the bottom-right frame, explaining interpretive problems the scribe might encounter. Auto-completion provides further context for interpretive difficulties (yes, "Hired Hand" is a valid option for the "Relationship" field).
Whoever entered the field metadata also recorded where, on the standard scanned image, that field was located. As you tab through the fields to transcribe, the corresponding field on the manuscript image is highlighted. It's hard to overstate how cool this is. It obviously required a vast amount of work to set up, but if you divide that by the number of pages in the Virginia census and subtract the massive amount of volunteer time it saves, I'd be astonished if wasn't worth the effort.
I have yet to see how FamilySearch Indexer handles freeform manuscript data. Their site mentions a Freedmans' letters project, but I haven't been able to access it through the software. Perhaps they've crafted a separate interface for letters, but based on how specialized their form-transcribing software is, I'm afraid they'd be as poor a fit for diaries as FromThePage would be for census forms.
Wednesday, May 30, 2007
Progress Report: Zoom
Zoom is done! It took me about a week of intense development, which translates to perhaps 8-10 hours of full-time work. Most of that was spent trying to figure out why
For the past year, I've been concentrating on automating the process of converting two directories of 180ish hastily-taken images into a single automated list of images that are appropriately orientated, reduced, and titled. Although this is not core to collaborative manuscript transcription — it would probably be unnecessary for a 5-page letter — it's essential to my own project.
As a result, the page transcription screen is still rudimentary, but I've gotten most of the image processing work out of the way, which will allow me to return the diaries I'm capturing Real Soon Now. Completing the transformation/collation process allowed me to work on features that are user/owner-visible, which is much more rewarding. Not only is this effort something I can show off, it's also the sort of work that Ruby on Rails excels at, so my application has progressed at a blazing clip.
I've still got a lot of administrative work left to do in allowing work owners to replace and manipulate page images, add new pages, or reorder pages within a work. This is not terribly difficult, but it's not quite sexy enough to blog or brag about. Zoom, on the other hand, is pretty cool.
prototype.js's Ajax.Request wasn't executing RJS commands sent back to it.For the past year, I've been concentrating on automating the process of converting two directories of 180ish hastily-taken images into a single automated list of images that are appropriately orientated, reduced, and titled. Although this is not core to collaborative manuscript transcription — it would probably be unnecessary for a 5-page letter — it's essential to my own project.
As a result, the page transcription screen is still rudimentary, but I've gotten most of the image processing work out of the way, which will allow me to return the diaries I'm capturing Real Soon Now. Completing the transformation/collation process allowed me to work on features that are user/owner-visible, which is much more rewarding. Not only is this effort something I can show off, it's also the sort of work that Ruby on Rails excels at, so my application has progressed at a blazing clip.
I've still got a lot of administrative work left to do in allowing work owners to replace and manipulate page images, add new pages, or reorder pages within a work. This is not terribly difficult, but it's not quite sexy enough to blog or brag about. Zoom, on the other hand, is pretty cool.
Monday, May 14, 2007
FamilySearch Indexing
Eastman's Online Genealogy Newsletter enthuses over the news that FamilySearch.com, the website of the Utah Genealogy Society of which Dan Lawyer is PM is putting public archives online. This service is provided through FamilySearch Indexing, which is a sort of clearinghouse for records transcribed by human volunteers.
FamilySearchIndexer is not quite true image-based transcription, however. Its goal is to connect researchers with the digitized images of the original records, which is an altogether different problem from transcription per se. Its volunteers are collaborating to create what is essentially searchable image metadata. This is perfect for supporting surname searches of the database, and is probably better than FromThePage for transcribing corpora of structured documents like census records. However, it is not full transcription -- at least that's what I gather from the instructions for their Freedman's Letters transcription project:
I'll be interested to download and play with the indexer -- apparently it's not a web app, but rather a thick Java client that communicates with a central server, much like the WPI Transcription Assistant.
FamilySearchIndexer is not quite true image-based transcription, however. Its goal is to connect researchers with the digitized images of the original records, which is an altogether different problem from transcription per se. Its volunteers are collaborating to create what is essentially searchable image metadata. This is perfect for supporting surname searches of the database, and is probably better than FromThePage for transcribing corpora of structured documents like census records. However, it is not full transcription -- at least that's what I gather from the instructions for their Freedman's Letters transcription project:
- It is important that every name on the image be captured whether it appears as the sender, the receiver, in the body, or on the backside image of the letter.
- This project will contain multiple names per image. However, the data entry area is set with the default amount of three data entry lines per image. You will need to adjust the number of lines to match the number of names found on the image.
I'll be interested to download and play with the indexer -- apparently it's not a web app, but rather a thick Java client that communicates with a central server, much like the WPI Transcription Assistant.
Name Update: Renanscribe?
Both my friends Prentiss Riddle and Coulter George
have suggested that I resolve my software name quandry by looking for placenames in Julia Brumfield's diaries. I like this suggestion, since it retains the connection to the project's origin and has potential for uniqueness. The most frequently mentioned placenames in the diaries are "Renan", "Straightstone", "Mount Airy", "Long Island", and "Cedar Forest".
Long Island and Mount Airy are probably each so common that they'll have the same problems that Julia does. Renan, on the other hand, has a neat connection to collaboration: Ernest Renan is now most famous for his definition of a nation as "having done great things together and wishing to do more."
So maybe "Renanscript" or "Renanscribe"?
have suggested that I resolve my software name quandry by looking for placenames in Julia Brumfield's diaries. I like this suggestion, since it retains the connection to the project's origin and has potential for uniqueness. The most frequently mentioned placenames in the diaries are "Renan", "Straightstone", "Mount Airy", "Long Island", and "Cedar Forest".
Long Island and Mount Airy are probably each so common that they'll have the same problems that Julia does. Renan, on the other hand, has a neat connection to collaboration: Ernest Renan is now most famous for his definition of a nation as "having done great things together and wishing to do more."
So maybe "Renanscript" or "Renanscribe"?
Wednesday, May 2, 2007
Feature: Zoom
Scanners and modern digital cameras can take photos at mind-bogglingly high resolutions. The 5 megapixel Canon SD400 I've used to capture the diary pages results in enormous files. Displaying them at screen resolution, the images are several times the size of the average monitor.
This kind of resolution is fantastic for resolving illegible words — from my testing, it seems to be as good or better than using a magnifying glass on the original documents. Unfortunately these original files are unwieldy: it takes a very long time to download the image to the browser, and once downloaded, displaying the files in a UI useful for transcription is basically impossible.
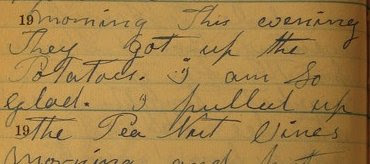
As a result, I'm shrinking the page images down by a quarter when they're added to the system. The resulting image is legible without much squinting. (See the sample above.)
These 480x640 images take up about half of the average modern monitor, so they're suited very well for a UI positioning the image on the right half of a webpage, with the textarea for transcriptions on the left half. They're also reasonably quick to load, even over a slow connection. They're not quite clear enough to resolve difficult handwriting, however, nor problems with the lighting when I took the original pictures. For that, we need to zoom.
In the original mockup created by my friend Blake Freeburg, as well as in the first prototype I wrote two years ago, a link appeared on the transcription page that reloaded the page with a higher resolution image. This provided access to the larger image, but had the same disadvantages (long wait time, ungainly UI) that comes along with larger image files.
The solution I've come up with is to provide a click-to-zoom interface. If a scribe can't read a part of the original, they click on the part they can't read. That will fire off an AJAX request including the coordinates they clicked. The server finds the next-larger-size image, crops out the section around the click target, and returns it to the browser. That will fire off an onComplete callback function to swap the standard-size image with the cropped version.
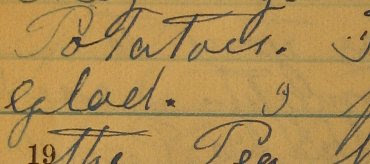
So in my example above. clicking the space after "glad." would return second image above. The user could then click an "unzoom" icon to return to the original low-resolution, full-page image, or click on the zoomed image to zoom again.
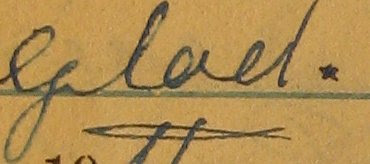
This would be the result of clicking on the zoomed word "glad" in the zoomed (second) image. This is a cropped version of the original five-megapixel image, and I think it's just as readable as the original document.
The advantages of this approach are a consistent UI and lower download times. Since some of my target users are rural or elderly, download time is a big plus.
The disadvantages come from possible need to pan around the zoomed image. My old colleague Prentiss Riddle has suggested using the Google Maps platform to provide tiled panning. This sounds elegant, but is probably hard enough to postpone until I have actual user feedback to deal with. There's also the possiblity that the server load for doing all that image manipulation will produce slow response times, but it's hard for me to imagine that the 45 sec needed to crop an image would take longer than downloading 1.5MB over a dialup connection.
This kind of resolution is fantastic for resolving illegible words — from my testing, it seems to be as good or better than using a magnifying glass on the original documents. Unfortunately these original files are unwieldy: it takes a very long time to download the image to the browser, and once downloaded, displaying the files in a UI useful for transcription is basically impossible.

As a result, I'm shrinking the page images down by a quarter when they're added to the system. The resulting image is legible without much squinting. (See the sample above.)
These 480x640 images take up about half of the average modern monitor, so they're suited very well for a UI positioning the image on the right half of a webpage, with the textarea for transcriptions on the left half. They're also reasonably quick to load, even over a slow connection. They're not quite clear enough to resolve difficult handwriting, however, nor problems with the lighting when I took the original pictures. For that, we need to zoom.
In the original mockup created by my friend Blake Freeburg, as well as in the first prototype I wrote two years ago, a link appeared on the transcription page that reloaded the page with a higher resolution image. This provided access to the larger image, but had the same disadvantages (long wait time, ungainly UI) that comes along with larger image files.
The solution I've come up with is to provide a click-to-zoom interface. If a scribe can't read a part of the original, they click on the part they can't read. That will fire off an AJAX request including the coordinates they clicked. The server finds the next-larger-size image, crops out the section around the click target, and returns it to the browser. That will fire off an onComplete callback function to swap the standard-size image with the cropped version.

So in my example above. clicking the space after "glad." would return second image above. The user could then click an "unzoom" icon to return to the original low-resolution, full-page image, or click on the zoomed image to zoom again.

This would be the result of clicking on the zoomed word "glad" in the zoomed (second) image. This is a cropped version of the original five-megapixel image, and I think it's just as readable as the original document.
The advantages of this approach are a consistent UI and lower download times. Since some of my target users are rural or elderly, download time is a big plus.
The disadvantages come from possible need to pan around the zoomed image. My old colleague Prentiss Riddle has suggested using the Google Maps platform to provide tiled panning. This sounds elegant, but is probably hard enough to postpone until I have actual user feedback to deal with. There's also the possiblity that the server load for doing all that image manipulation will produce slow response times, but it's hard for me to imagine that the 45 sec needed to crop an image would take longer than downloading 1.5MB over a dialup connection.
Subscribe to:
Posts (Atom)